Concept
An imagined product, mocked up by Claude Design.
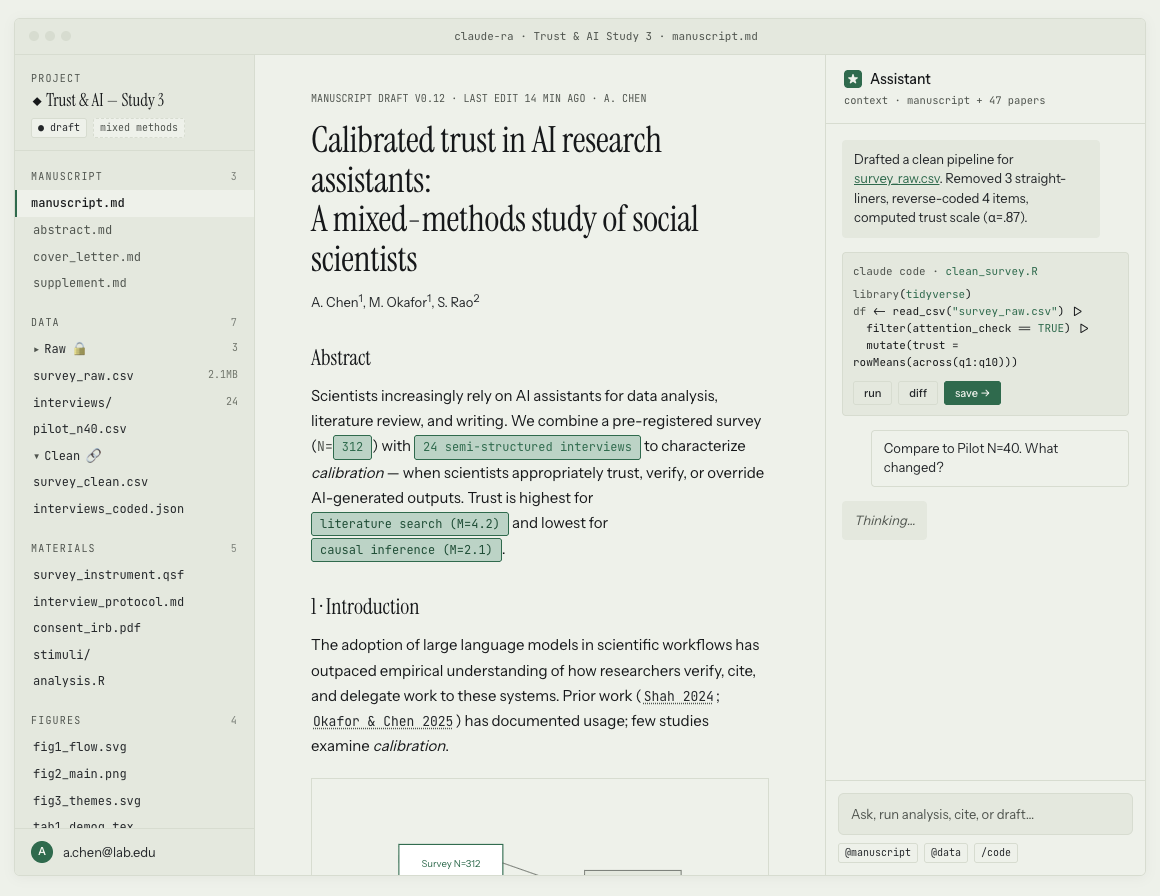
Welcome to Manuscript.
An imagined product. Inspired by Claude Design, mocked up for academic research.
If Manuscript existed, I could open it and find every part of a study in one place.
The instruments I built — surveys, protocols, consent forms.
The papers I read in the run-up.
The data those instruments collected.
The figures I drew from it.
And at the center of it all, the paper itself.
What follows is a walk through what that might look like. None of it works.
01 — Materials
Where a study begins.
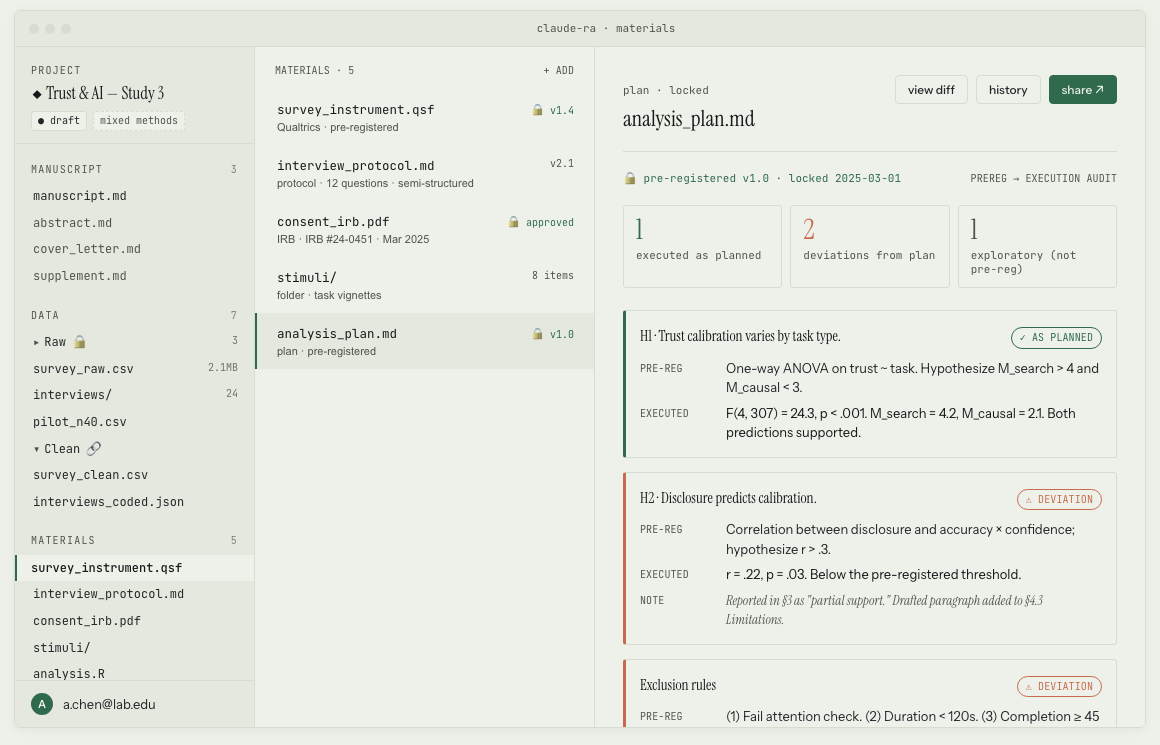
Every empirical paper stands on its instruments: the survey, the interview protocol, the consent form, the pre-analysis plan. Most of us keep these scattered in folders on our computers, if we keep them at all. Some of us re-download the survey from Qualtrics or the pre-registration from AsPredicted every time we need one. In Manuscript they would sit together, versioned, so nothing is lost.
For example, the pre-registration is a commit, not a PDF. Every deviation from the plan is a row in an audit log: visible, named, and automatically drafted into the limitations paragraph for me to tighten later.
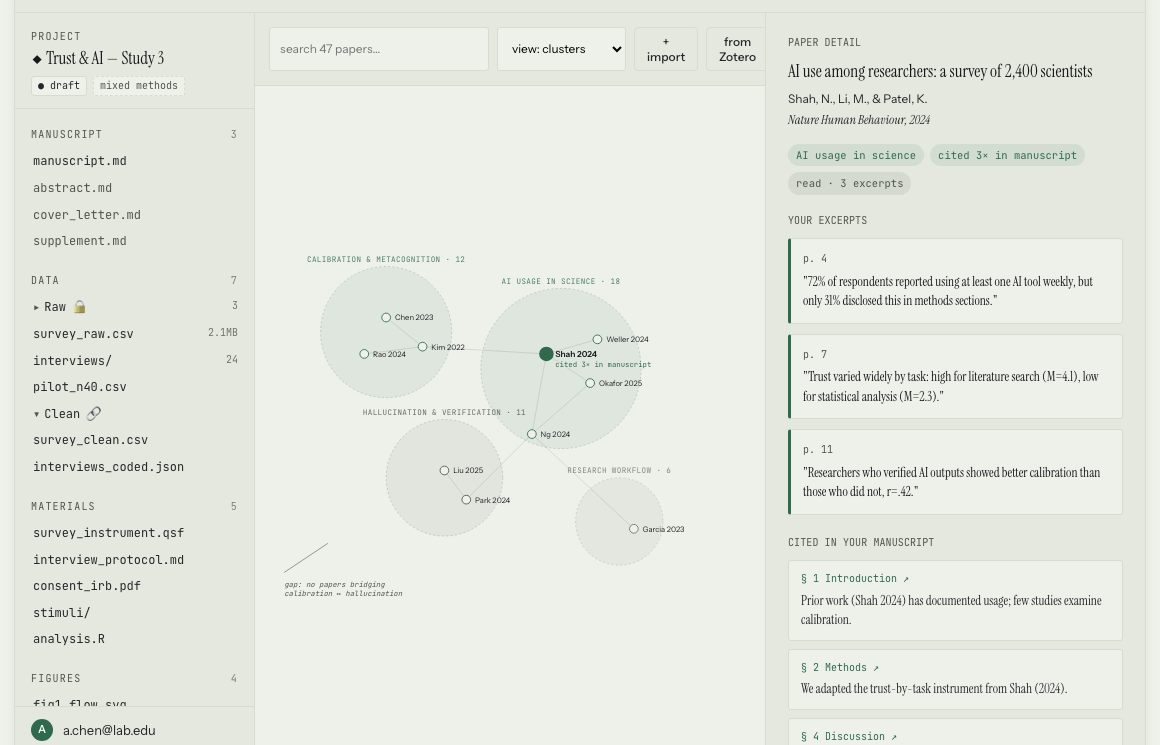
Manuscript could ingest a reading list, files, photos, or entire books into a project library. It would borrow tools we already see in Google's NotebookLM and Obsidian — the library turns into a graph, papers cluster by theme. For the papers you've read, you can collect excerpts. For those you haven't but cite because reviewers asked you to, it surfaces the relevant sections. Citations become a nudge: when you include a source, you're prompted to tie it back to an excerpt. No hallucinations — from the machine or the human — when you have to cite your sources this way.
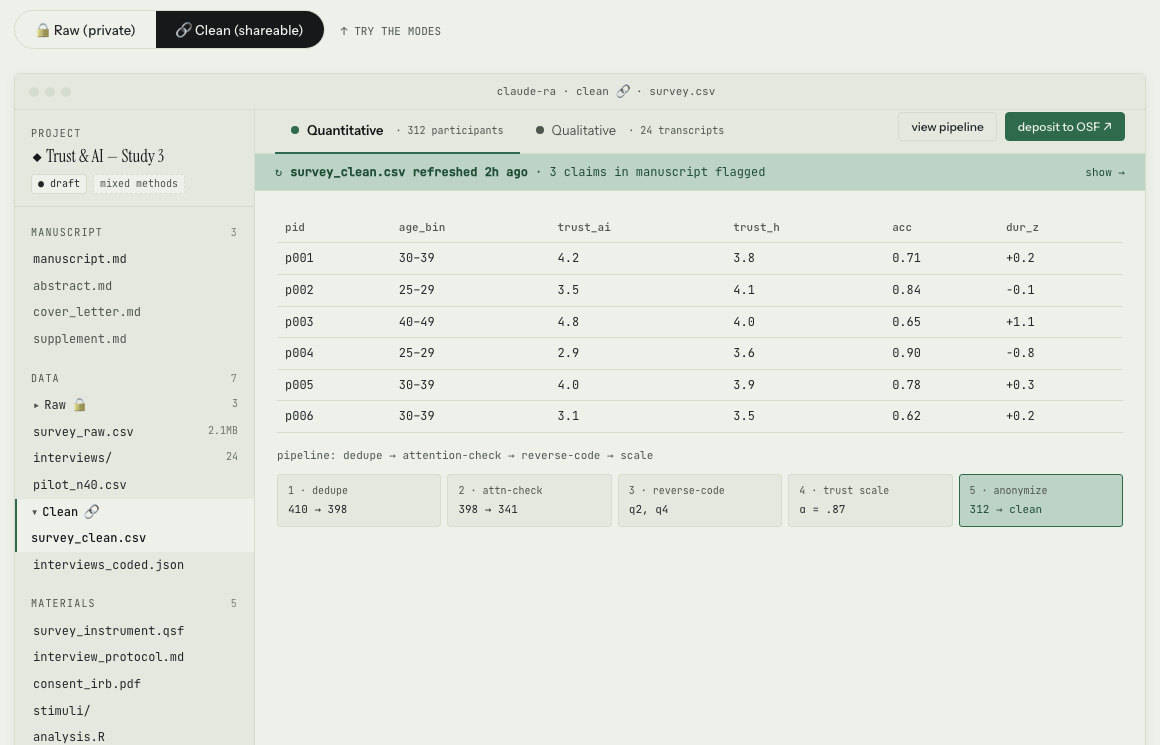
Raw data is protected. Cleaned data is made accessible.
Raw and Clean live side by side. Raw is encrypted, PII-flagged, and never leaves the device. Clean is anonymized, pipeline-traced so viewers can see how it was cleaned, and ready to deposit at OSF. Manuscript would treat qualitative and quantitative data alike, checking for errors and summarizing descriptives on demand.
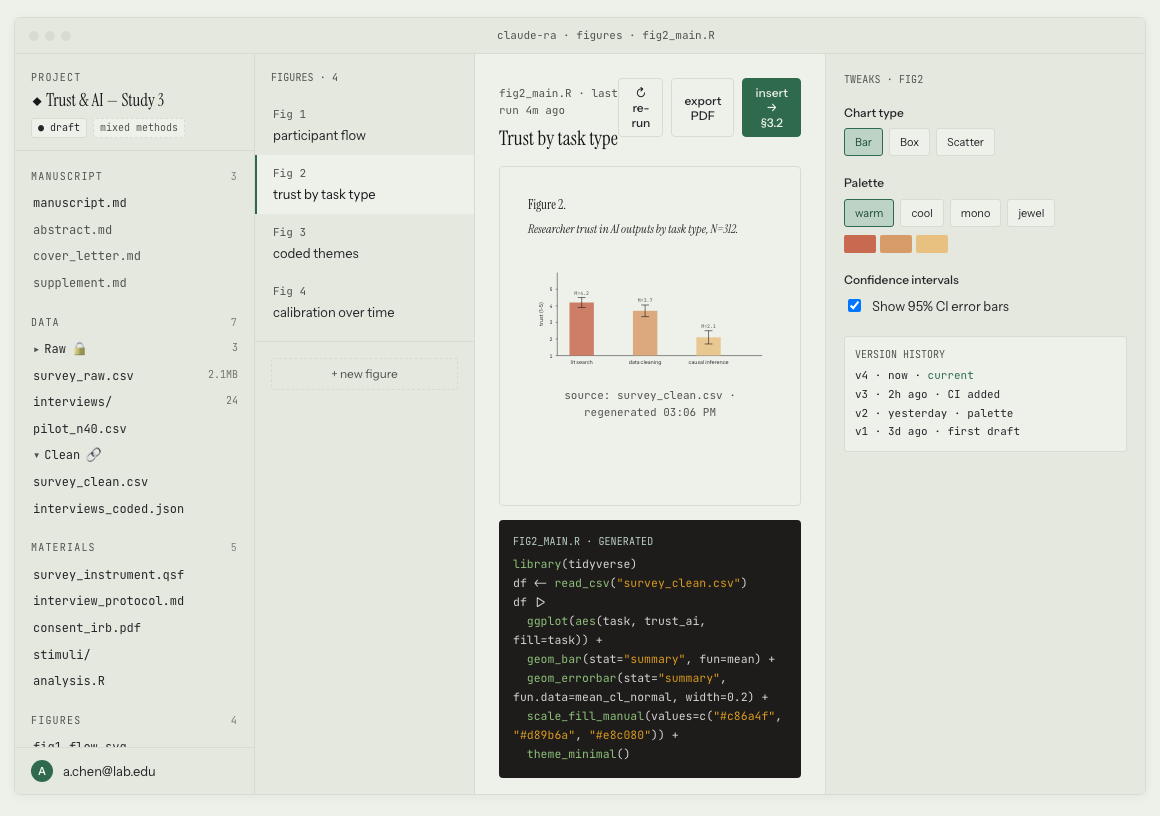
In Manuscript a figure is a live R script bound to clean data. Borrowing Claude Design's "Tweaks," you could change the palette, toggle error bars, or swap in a different figure type with a single click — the figure redraws, the script regenerates, and the new version drops into your manuscript. If the data changes for any reason, the figure refreshes too. No more re-export, re-paste, and hope it's the right version.
One file, three views. Draft is the work in progress, with links back to specific analyses, datasets, and highlighted excerpts. Publication is what the journal sees — typeset and polished. Interactive is what a reader sees on the web, where the numbers are live and they can filter the data themselves. The text doesn't have to change between views; the template does. Switching journals means picking a different template, not re-formatting by hand.
But it could. The Library draws on features from Google's NotebookLM, Obsidian, and DEVONThink. Data and Figures draw on Claude Code and OpenAI's Codex, which have made cleaning, wrangling, analyzing, and visualizing data efficient and accessible. DEVONThink shows this can live on our personal machines; Manuscript would be the wrapper, organizing the system most of us already use. Claude Design makes clear that a system like this is not in the distant future; it was both the inspiration and the assistant behind the frontend shown here.
For an afternoon's worth of work, it was fun to imagine what the future holds for research. A tool like this would be disruptive for academia but not necessarily for academics. Academia, as a system, treats publications as a proxy for excellence — the currency of hiring and promotion — and journals profit immensely from a cycle bound to publish-or-perish. Academics, meanwhile, labor countless hours in service of that cycle. The job involves too many hours of bookkeeping — formatting tables, redrawing figures, cross-checking sources, managing versions sent and received and revised — and comparatively few on advancing ideas. Manuscript, if designed well, would absorb this tax. The slow parts of research would get faster and more reliable, freeing time for the parts that move science forward: thinking, discussing, inventing.
Before the more polished mocks above, Claude Design produced a set of rough wireframes — notes, arrows, IA experiments. You can see them preserved here.